These are the speaker notes of a talk I gave at the New Hampshire Archives Group Spring 2022 Workshop on [[May 17th, 2022]]
Good afternoon, everyone. Thank you for coming to my presentation when you could just leave and go outside. My name is Jay L. Colbert, and today I’ll be presenting “Describing Absence: The Complicated Power of Metadata Surrogates in Libraries & Archives”
Advanced notice that this presentation will mention suicide and potentially upsetting language. I will warn you before those slides.
There is also a slide with a YouTube video.
Contents
First, I’ll tell you a bit about myself and why I’m talking about this issue.
Next, I’ll define some of the ideas central to this presentation. It’s important that you are aware of how I’m using these terms so that we’re all on the same page.
Then, I’ll discuss archival silence and why it’s such a problem, using three examples.
And before we move on, I’ll do a brief intermission, which will lead us into…
why archival silence can actually be a good thing. I know, a bit spicy considering the theme of this workshop.
Who am I
So, who am I.
I’m the Metadata & Discovery Strategy Librarian at the University of New Hampshire, with Assistant Professor Rank. I am also the Metadata Librarian for the New Hampshire Digital Library and our emerging project to become a DPLA hub.
I am on the Editorial Board for the Homosaurus, an international LGBTQ linked data vocabulary. It is a controlled vocabulary, and galleries, libraries, archives, and museums all over the world use it in their descriptive metadata. If you are curious about using it in your collections, please reach out to me.
And…I am not an archivist. I have worked with EADXML, but I have no formal archival training. The archivists, in the room and on Zoom, you are the experts, not me. If I am completely misunderstanding something, feel free to let me know.
Definitions
Moving on to our definitions.
Please forgive me if this first definition seems elementary. We’ve all heard the “metadata is data about data” definition. And while that definition is accurate, I find it unhelpful for describing what metadata is for and what it can do.
Instead, I like the definition from the Getty book Introduction to Metadata. Thanks to Elliot Williams who assigns sections of this book in his Metadata and Description for Digital Special Collections Library Juice Academy course.
“Perhaps a more useful, “big picture” way of thinking about metadata is as the sum total of what one can say at a given moment about any information object at any level of aggregation. In this context, an information object is anything that can be addressed and manipulated as a discrete entity by a human being or an information system. The object may be a single item, an aggregate of many items, or an entire database or record-keeping system. Indeed, in any given instance one can expect to find metadata relevant to any information object existing simultaneously at the item, aggregate, and system levels.”1
For example, your driver’s license, if you have one, has metadata that describes you. But if you move, get a different class of license, etc, in ten years, that metadata will change.
And because that metadata is what can be said about you, a person, it can also be viewed as a surrogate.
Again, from the Introduction to Metadata book, digital surrogates are the digital versions of “actual” collection content, and descriptive surrogates are the description of that content. If my library scans the Town Report of Dover in 1962, that PDF or whatever file format is the digital surrogate and the metadata record my colleagues create is the descriptive surrogate. In an AV course I took in grad school, the professor even said that a metadata surrogate can be a form of preservation; if it’s good enough, someone might not need to interact with the physical object.
Finally, archival silence. The Society of American Archivists defines it as “the unintentional or purposeful absence or distortion of documentation of enduring value, resulting in gaps and inabilities to represent the past accurately.”2
I have some criticisms of this definition. First, it does not mention the destruction of documentation. Second, what does “enduring value” mean. Who gets to decide what has value and what does not? And finally, it is impossible to accurately represent the past, and why must silence only happen in contexts where we’re trying to represent the past.
When archival silence is bad…
An immediate example: this photo is from a collection of warped headshots from a theater company. The name of the man in the photo is not given.
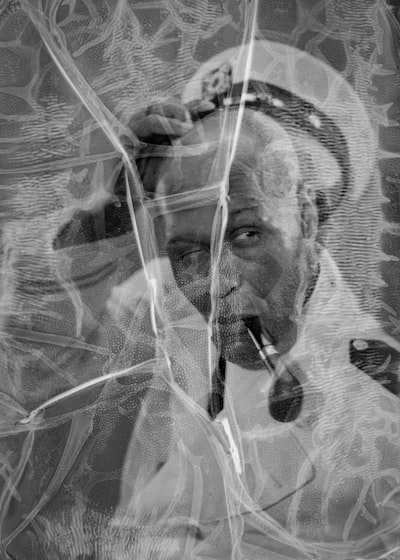
The article [[The Image of Absence: Archival Silence]] by [[Lauren F. Klein]] begins with an excerpt of a letter Thomas Jefferson wrote to his friend William Evans.
You mentioned to me in conversation here that you sometimes saw my former servant James, & that he made his engagements such as to keep himself always free to come to me. Could I get the favor of you to send for him & tell him I shall be glad to receive him as soon as he can come to me?
Although this letter does not name him, the “former servant James” is James Hemings, the brother of Sally Hemings, as well as an accomplished chef.
So why does the descriptive surrogate matter so much here?
“The only reason this letter appears in the list of results for a keyword search on “James Hemings” is that the editors of the Papers of Thomas Jefferson have noted that the “former servant” refers to Hemings, and this information has been added to the digital version of the document as metadata. Because the default scope of a keyword search in the Digital Edition includes this extratextual information, as well as the text of the document itself, a researcher need not distinguish between textual content and editorial note. But should the researcher begin, instead, with a “Name” search for James Hemings as either an author or a recipient of a letter, even across the estimated 25,000 documents that the Digital Edition presently contains, he or she would be returned no results.”
Next, we have the Utah American Indian Digital Archive. I used to work at the University of Utah, where I did a project with the Utah American Indian Digital Archive. I analyzed their metadata to look at silences and other ethical concerns, and I developed a best practices for describing items related to Indigenous people. For example, how many photos had an “Unnamed Navajo woman” next to a named Mormon missionary settler colonizer? How many documents used language like “problems with Indians” and “savages?” Even though the Ute and Navajo people are represented in this collection, that terminology is a distortion, as it gives the point of view of the colonizers. However, I would not want to get rid of that information. It is more important to reckon with our mistakes than to obfuscate them.3
A suggestion I made was to not authority control for Mormon settlers in photographs with unnamed Indigenous people. Put that information in a notes field so it’s indexed and discoverable, but do not provide that access point.
If there are silences we cannot fix, make them loud.
Finally, I want to tell you about Bibliographer B. A quick lesson about the study of Shakespeare Compositors. Particularly before WWII, a popular form of research in Shakespeare studies was looking at the folios and whatnot and trying to parse out who put it together and edited it, and if that person composited others. This takes a lot of linguistic analysis, studying how someone writes and spells, their editing choices, all that.
It should not be surprising, therefore, that, when some of these men fought in WWII, they used those skills for cryptography and espionage.
“But hiatus, to backtrack for a moment, is not the best word for what happened to American bibliographic study during the Second World War, for, as I want to suggest, compositor analysis was not so much suspended as produced by the war, in some important ways. Before the United States entered the war, Bowers “had been given secret instruction as a cryptanalyst in a naval communications group being formed at the university [of Virginia]”; during the war he moved to Washington “to supervise an intelligence unit working on deciphering enemy codes.” Among a number of prominent literary/bibliographic scholars, the unit included Charlton Hinman. Hinman in fact got the idea for the collating machine he later invented to compare Shakespeare folio pages from “the method followed in the intelligence unit for comparing successive photographs of enemy fortifications, to see whether changes had been made.””4
After, a little something called McCarthyism happens. Removing Communists from government positions and higher education. But also, there was the Lavender Scare, of also removing queer people from government positions and higher education.
But you can’t just look at someone and tell that they’re queer. Instead, to root out homosexuality, they studied their behaviors, their affects, any visible signs they could find.
This brings us to Bibliographer B, who studied Shakespeare Compositors at the University of Virginia.
“He published in Studies on compositor analysis in a number of Shakespeare plays, and, early one morning in March of 1955—and now I am quoting from the local newspapers—Bibliographer B, “who was 37 and unmarried, shot himself in the right side of the head with a .22 calibre pistol.””5
The reports of his suicide also mention that he was found cleanly shaven and dressed, as if they expected him to be otherwise. The reports are basically doing everything but calling him a “confirmed bachelor.” They don’t say he’s gay, but that silence tells us everything.
Especially considering that a set of papers related to his death, including committee reports on his case, have been destroyed by the University of Virginia. Jeffrey Masten, the author of the book [[Queer philologies: sex, language, and affect in Shakespeare’s time]] , contacted the special collections at UVA and learned that the documents were destroyed “according to the records management guidelines enacted by the Commonwealth of Virginia.”
Brief intermission on data privacy and surveillance
A brief intermission about privacy and surveillance.
Privacy is our right to choose when, how, why, and how much we share information about ourselves.
Our privacy is violated constantly by corporate tracking and data mining, and government surveillance.
Raise your hand if you’ve ever gone into your Facebook settings and looked at the “ad preferences.” It guesses all this information about what you like, your political affiliations, your sexuality, all sorts of things. You can go in and edit it, but it’s opt-out, not opt-in.
Facebook, Google, Amazon, and loads of other corporations track your browsing habits and mine data from your phone, as well.
Facebook can do this even if you don’t have a Facebook account.
In a capitalist society, governments and corporations construct surrogates of us from the data they mine. And in a capitalist society, that data surrogate is more “real” and has more value than we do because it makes them money. Everything about us is exploited, and we do not even know the true extent of that exploitation. Except that it can absolutely be used against us when we are no longer valuable.
…and when it’s good
Therefore, it is not always a bad thing to have silences in our collections. Sometimes, those silences are necessary.
Privacy and legality
We have two examples of archives and special collections potentially (and actually) exposing the participants of oral histories to criminalization.
The first is The Belfast Project at Boston College which collected the oral histories of IRA members. There were several protocols put in place to protect participants.
- First, the participants were referred to under pseudonyms, and only one person could have the entire key that detailed who was who.
- Secondly, nobody external to the project was supposed to know about it.
Those outside of the Boston College Library were not to be trusted or consulted with in regards to any knowledge of the project. This meant that everything, from the legal documents to the documentation and storage of the interviews, was kept secret from all Boston College experts, lawyers, and consultants.
- Finally, the tapes were not to be released until after their respective interviewees had died. However, they made a major mistake: they did not consider that people mentioned in the interviews might still be alive when the tapes were released.
In 2008, Brendan Hughes, a former IRA fighter, died.
In 2010, Ed Moloney released a book which used Hughes’ tapes. And in that was information about Jean McConville, a “Disappeared” woman assumed to be murdered by the IRA. Naturally, the tapes–now known to the public–were subpoenaed. And guess what? The interviews had not been properly redacted nor did Boston College have a proper redaction policy. An IRA member, Ivor Bell, was sentenced to a “trial of the facts” because of his deteriorating mental health. The judge ruled the Boston College tapes were not admissible, however, and Bell walked free.6
Then there’s the Histories of Choice collection at Florida Gulf University, “an ethnographic recollection of Roe v. Wade that provides historical context of different perspectives and lived experiences centered around the theme of abortion.” The issue: some of these oral histories contain information from when abortion was criminalized. And in our current climate, and even in some states currently, the information that might not be criminalized now could be in the future. How do we ensure access, including with our descriptive metadata, that will not result in criminalization? What is the statute of limitations? How can we protect these people?
Their solution: staff members who were comfortable with the subject matter redacted PII: name, age, location, hometown, graduation year, etc. Then they would swap transcripts and do the redaction process again. The names of participants were also removed from all master metadata and accession records. All previous versions of the transcripts were deleted, as were the original audio recordings. The public record of the project is the only record in existence; there is no additional data for a legal entity to subpoena.7
Government interference
This next example is hypothetical.
I have a colleague and friend in Texas who had begun working on a project concerning oral history projects with undocumented immigrants, and the ethical and legal challenges of doing so. He was kind enough to share his notes with me when I was talking about my presentation with him.
In those notes, a strategy he and his collaborators came up with was to “go through the worst case scenario”:
Oral history program gets started, all the recommendations we’ve made are put into place. Some of the redacted materials are released or publicized and anger anti-immigrant groups. We then begin receiving FOIA requests so they can attempt to identify the subjects in the interviews and report them to ICE or find other incriminating evidence against the participants. Because we’ve destroyed the originals with PII, it’s unlikely, but with all the information people can glean online, these FOIA’d items could then end up on a public website for people to attempt to identify the subjects who have been anonymized. At this point the library wields its copyright to take down the website before the subjects can be identified. This may garner more scrutiny for the university, but at least the actual process of doxxing people who have entrusted us with their stories can be halted. Also, it’s worth pointing out that doing nothing will also not put a stop to this harassment campaign.
This could also apply to other scenarios, such as oral histories of domestic abuse where abusers might recognize themselves in a story and attempt to get the current information on their victims.
Giving space back
Not every culture, group, or community is going to have the same knowledge management, knowledge transmission, or knowledge organization systems as the dominant library/archival science framework. There are oral traditions of music transmission, there are Tibetan Buddhist practices that are only shared between lama and student in an unending lineage back to the Buddha, there are traditions where information is only shared within that group. I am not one who advocates for our default diversity, equity, and inclusion response to be absorbing the systems of other cultures into our own, creating a mono-system. Instead, I advocate for giving space back to these other ways of describing information, as well as working with communities to see where sharing and collaboration can happen with mutual trust.8
What may sound like silence to us could actually be an orchestra to another culture.
Other ways of archiving
In addition to there being cultures whose descriptive and archival practices differ from the dominant’s, I argue that even within our culture there are ways of describing certain information and experiences better than could be done in a finding aid.
An example and analysis I love comes from the article [[Archiving the Wonders of Testosterone Via YouTube]] by [[Tobias Raun]] :
The article engages with trans male video blogs on YouTube, framing them as living archives that offer unique opportunities to access and share embodied trans knowledges—which have previously been limited or inaccessible—such as information about and visual accounts of medical transitioning processes. It is argued that archiving one’s transition works through a kind of performative documentation, partly documenting and partly instantiating the transformation by tracking and tracing the bodily changes.9
I cannot get enough of the idea that a trans man documenting his transition and experience with HRT via YouTube is creating metadata from, with, and of his body. If metadata is the sum total of what can be said about any information object at any given time, then the bodies of trans people undergoing medical forms of transition are living, always-changing metadata records. They are the information object, and they are also what can be said about the information object.
My transsexual body is a catalog, a finding aid, of every testosterone injection I have given myself in my thigh, of the parts of my body I have willingly destroyed to create something better in their wake, of the process of teaching myself to shave my face (which is way different than shaving your legs, it turns out), of the ways my sexuality changed, of the hours of speech and movement therapy I did, of the fact that I’m still afraid to use gendered bathrooms in public after 4 years. That cannot be represented in a finding aid, no matter how hard we might try. I’m not saying we shouldn’t try, but I think we need to admit our shortcomings and accept them.
I also want us to think about representation, and why we’re trying to put it in our metadata. Is it to actually connect with communities? Or is it to go along with the thing you think is right because you saw three other institutions do it on Twitter and you don’t want to look bad?
What is more important: representation, or the material reality and consequences that our good-faith efforts can affect?
Permission to FORGET
Even outside of our silences, we need to face one inevitable fact: we cannot describe and collect all information. In fact, we might lose it, damage it, destroy it, or fail to get it in the first place.
That’s okay.
Nothing is permanent. When we accept that, we can better prepare for the gradual loss of information.
We do not take care of the shadows
I was reading a newsletter by Robin Rendle where he mentioned the book In Praise of Shadows by Junichiro Tanizaki. A main argument of this book is that Westerners do not appreciate shadows. We put lamps everywhere, trying to fill every space with light. But what if we treated our shadows with the same respect? What if we saw the beauty in them, how they bring form to emptiness,10 how they define the beauty of the surrounding light?
In that newsletter, Robin says,
“(We do not take care of the shadows.)”
We do not take care of our silences, good or bad, and I think we should.
[[Setting the Stage]] , Introduction to Metadata ↩︎
[[@archival silence]] Dictionary of Archives Terminology ↩︎
See [[Queering the Catalog: Queer Theory and the Politics of Correction]] by [[Emily Drabinski]] ↩︎
[[Queer philologies: sex, language, and affect in Shakespeare’s time]] by [[Jeffrey Masten]] ↩︎
Ibid. ↩︎
[[The Belfast Project: How an American University almost Started a Civil War]] by [[Andres Ruiz]] ↩︎
[[Testimonies: The rewards and challenges of letting their voices be heard]] by [[Melissa Minds VandeBurgt]], [[Bailey Mae Rodgers]], and [[Kinsey Brown]] ↩︎
Fun fact: in order to be a professionally registered librarian in Aotearoa (New Zealand), you have to demonstrate competency in Māori knowledge systems. ↩︎
Emphasis mine ↩︎
Sorry to keep getting Buddhist on main. ↩︎